
Text analytics is a game-changer for businesses looking to extract insights from the vast amounts of data they collect.
But are you making the most of this powerful technology?
In this blog post, we’ll explore advanced text analytics techniques that can take your business to the next level. From uncovering hidden patterns with text mining, to automatically categorizing documents with natural language processing, these techniques will help you gain a deeper understanding of your customers, streamline your operations, and make data-driven decisions.
If you’re ready to go beyond the basics and unlock the full potential of text analytics, keep reading.
What Is Text Analytics?
Text analytics extracts insights from unstructured text data by using natural language processing (NLP) and statistical analysis to identify patterns, sentiments, and key characteristics within large volumes of text. The goal is to transform raw, unstructured data into structured, actionable insights that can support data-driven decision-making.
Example of Text Analytics
Teams can use text analytics to analyze customer reviews and assess overall sentiment. This information can then be used to improve products, services, and customer experience. Analyzing customer support tickets can help identify patterns in customer issues and feedback, which can be instrumental in enhancing product features or service quality.
Analyzing customer surveys (especially open-ended responses) allows companies to extract patterns and insights. This analysis can be particularly useful in understanding customer satisfaction through NPS responses, feedback, and support interactions across various channels like email, chat, and social media, thereby enabling more data-driven decisions to improve customer engagement and service delivery.
Other examples of text analytics:
Social media monitoring to track brand perception and customer engagement
Support ticket analysis to identify opportunities to improve customer experience
Survey data analysis to mine context from open-ended questions
Is Text Analytics the Same as NLP?
While text analytics and NLP are closely related, they are not exactly the same. NLP is a subfield of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language. It involves tasks such as part-of-speech tagging, named entity recognition, and sentiment analysis. Text analytics, on the other hand, is a broader field that encompasses NLP techniques along with other methods for extracting insights from text data. This can include statistical analysis, data visualization, and machine learning algorithms.
In other words, NLP is a key component of text analytics, but text analytics goes beyond just NLP to provide a more comprehensive approach to deriving value from unstructured text data.
The Need for Text Analytics
In today’s digital age, the volume of unstructured text data is growing exponentially.
This includes emails, social media posts, customer reviews, and more. Additionally, analyzing external data from sources like social media, online reviews, and forums is crucial for gaining comprehensive insights. According to some estimates, unstructured data accounts for up to 90 percent of all enterprise data. Without text analytics, this valuable data, including external data collected through web scraping tools, APIs, and open datasets, would remain largely untapped. By applying text analytics techniques, organizations can gain a deeper understanding of their customers, operations, and market trends. This can lead to better decision-making, improved efficiency, and competitive advantage.
7 Powerful Text Analytics Techniques to Boost Your Business
Text analytics techniques, including advanced deep learning algorithms and machine learning based systems, can help businesses gain valuable insights from unstructured text data. By leveraging these techniques, you can:
Uncover hidden patterns and relationships in large text corpora
Gauge customer sentiment and opinions from feedback and reviews, with deep learning algorithms providing semantically rich representations for more accurate sentiment analysis
Automate document categorization and streamline information retrieval, enhancing text analysis and classification through machine learning based systems

1. Text Mining: Uncovering Hidden Insights
Text mining involves extracting valuable information and patterns from unstructured text data. It allows businesses to identify trends, relationships, and key themes in large data sets.
Here are some key was you can leverage text mining to uncover hidden insights:
Extract Insights from Unstructured Data
Unstructured data, such as customer reviews, social media posts, and email conversations, often contain insights that can inform critical business decisions. Text mining techniques enable you to extract key insights by analyzing the content and context of the data. Data visualization can then be used to present the extracted insights effectively.
One common approach is to use natural language processing (NLP) algorithms to preprocess the text. This involves tasks like tokenization (breaking text into individual words or phrases), removing stop words (common words like “the” or “and”), and stemming or lemmatization (reducing words to their base or dictionary form). By cleaning and normalizing the data, businesses can prepare it for further analysis.
Identifying Trends and Relationships
Once the data is preprocessed, various techniques, including statistical analysis, can be applied to identify trends and relationships. Some popular methods include:
Frequency analysis: Counting the occurrence of specific words or phrases to determine their relative importance or popularity.
Co-occurrence analysis: Examining the frequency with which certain words or phrases appear together, indicating potential relationships or associations.
Collocation analysis: Identifying words that commonly occur in close proximity to each other, suggesting strong associations or idiomatic expressions.
By applying these techniques, businesses can uncover hidden patterns and gain insights into customer preferences, market trends, and emerging topics of interest.
2. Sentiment Analysis: Gauging Emotions and Opinions
Sentiment analysis involves determining the overall sentiment (positive, negative, or neutral) expressed in a piece of text. This technique is particularly useful for analyzing customer feedback, social media posts, and product reviews.
Understanding Customer Sentiment
Sentiment analysis enables businesses to gauge the emotions and opinions of their customers. By analyzing the sentiment expressed in customer feedback, businesses can identify areas of satisfaction or dissatisfaction, as well as potential issues or concerns. Data visualization can be used to present sentiment analysis results effectively.
There are various approaches to sentiment analysis, ranging from rule-based methods to machine learning algorithms. Rule-based methods rely on predefined sentiment lexicons or dictionaries that assign sentiment scores to words or phrases. Machine learning algorithms, on the other hand, learn from labeled training data to classify sentiment based on patterns and features in the text.
Applications of Sentiment Analysis
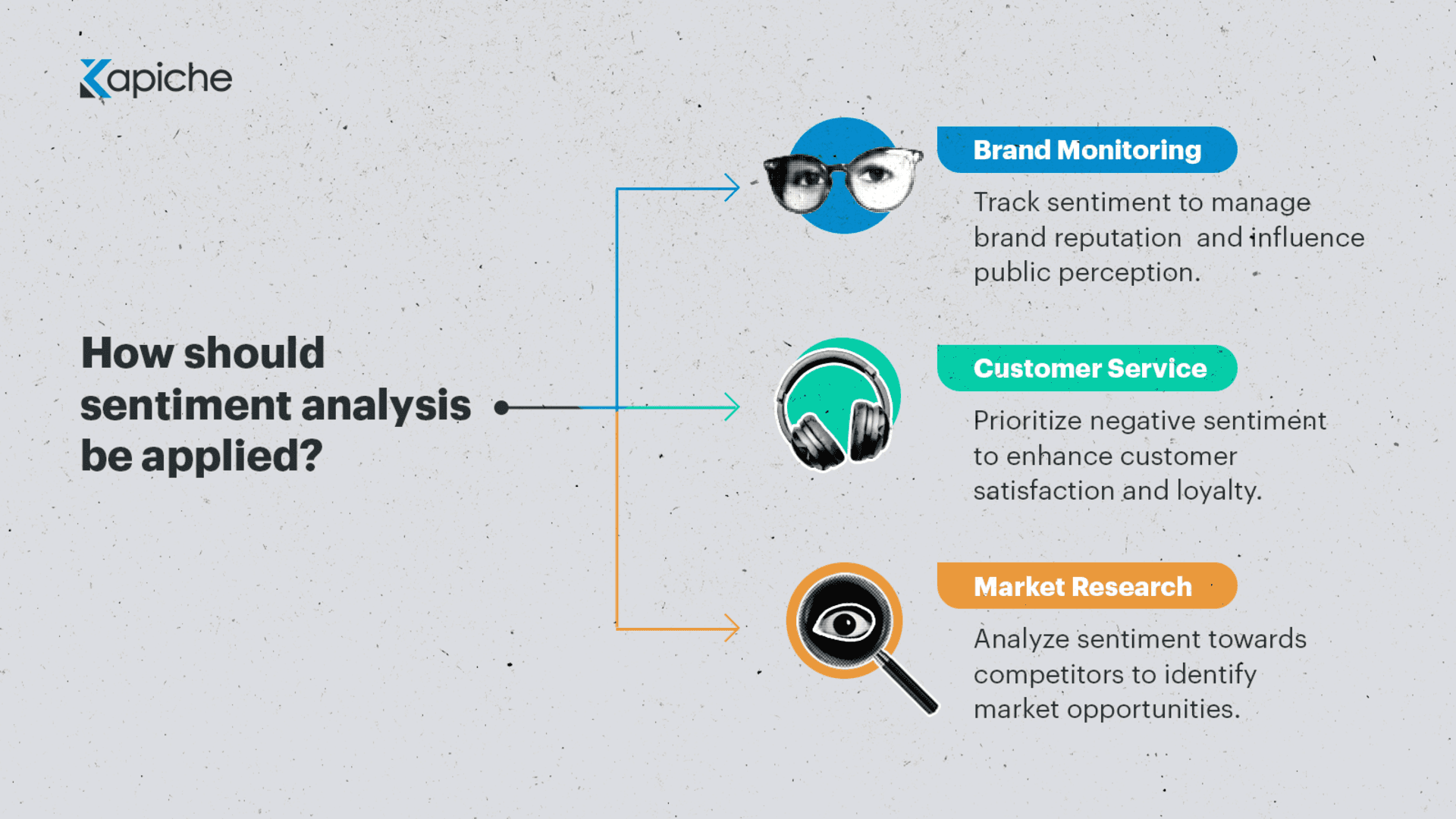
Sentiment analysis has numerous applications across different industries. Some common use cases include:
Brand monitoring: Tracking sentiment towards a brand, product, or service across social media platforms and online reviews.
Customer service: Identifying and prioritizing negative sentiment to address customer complaints and improve satisfaction.
Market research: Analyzing sentiment towards competitors or industry trends to gain a competitive advantage.
By leveraging sentiment analysis, businesses can proactively address customer concerns, improve product offerings, and make data-driven decisions based on customer sentiment.
3. Named Entity Recognition (NER): Identifying Key Elements
Named Entity Recognition (NER) is a text analytics technique that automatically detects and classifies named entities, such as people, organizations, and locations, in unstructured text data. NER helps extract structured information from unstructured text, enabling businesses to identify key elements and gain valuable insights.
Extracting Named Entities
NER algorithms use a combination of linguistic rules, statistical analysis, statistical models, and machine learning techniques to identify and classify named entities in text. These algorithms are trained on large annotated datasets, where named entities are manually labeled and categorized.
Common named entity types include:
Person names: Identifying individuals mentioned in the text, such as customers, employees, or public figures.
Organization names: Recognizing companies, institutions, or other organizational entities.
Location names: Detecting geographic locations, such as cities, countries, or landmarks.
Date and time expressions: Extracting temporal information, including specific dates, times, or durations.
By automatically extracting named entities, businesses can structure and organize the data, making it easier to analyze and derive insights.
Applications of Named Entity Recognition
NER has various applications across different domains, including:
Customer relationship management (CRM): Identifying customer names and details from email conversations or support tickets to enhance personalization and improve customer service.
Information retrieval: Indexing and searching for specific entities within large document collections or knowledge bases.
Content recommendation: Personalizing content recommendations based on the entities mentioned in user-generated content or user profiles.
NER enables businesses to extract valuable structured information from unstructured text data, facilitating more efficient analysis and decision-making.
4. Topic Modeling: Discovering Latent Themes
Topic modelling is a text analytics technique that identifies the main topics and themes in a collection of documents. It helps businesses categorize and organize large volumes of text data based on content similarity.
Uncovering Latent Topics
Topic modelling algorithms, such as Latent Dirichlet Allocation (LDA) or Non-negative Matrix Factorization (NMF), automatically discover latent topics in a document corpus. These algorithms treat each document as a mixture of topics and assign a probability distribution over topics to each document. Data visualization can be used to present the discovered topics effectively.
The process of topic modelling typically involves the following steps:
Preprocessing: Cleaning and normalizing the data, including tokenization, removing stop words, and stemming or lemmatization.
Feature extraction: Converting the preprocessed text into a numerical representation, such as a document-term matrix or a term frequency-inverse document frequency (TF-IDF) matrix.
Topic modeling: Applying the chosen topic modeling algorithm to the feature matrix to discover latent topics and their associated word distributions.
Interpretation: Analyzing the discovered topics and their associated words to understand the underlying themes and concepts in the document corpus.
By uncovering latent topics, businesses can gain a high-level understanding of the content and themes present in large text corpora without manually reading and categorizing each document.
Applications of Topic Modeling
Topic modeling has various applications in business, including:
Content analysis: Identifying the main topics and themes in customer feedback, product reviews, or social media discussions to understand customer preferences and sentiments.
Document organization: Automatically categorizing and organizing large collections of documents based on their content similarity, facilitating efficient information retrieval and knowledge management.
Trend analysis: Tracking the evolution of topics over time to identify emerging trends, shifts in customer interests, or changes in market dynamics.
Topic modelling enables businesses to extract meaningful insights from large volumes of unstructured text data, leading to improved decision-making and content strategy.
5. Text Classification: Automating Document Categorization
Text classification is a text analytics technique that automatically assigns predefined categories or labels to text documents. It streamlines document organization and information retrieval by automatically categorizing documents based on their content.
Supervised Learning for Text Classification
Text classification typically relies on supervised learning algorithms, including statistical analysis, where a model is trained on a labeled dataset consisting of documents and their corresponding categories. The algorithm learns the patterns and features associated with each category and uses this knowledge to classify new, unseen documents.
Common supervised learning algorithms used for classification include:
Naive Bayes: A probabilistic algorithm that assumes the features (words) in a document are independent of each other given the class label.
Support Vector Machines (SVM): An algorithm that finds the optimal hyperplane separating different classes in a high-dimensional feature space.
Logistic Regression: A statistical model that estimates the probability of a document belonging to a particular class based on its features.
By training a classification model on a labeled dataset, businesses can automate the process of categorizing new documents, saving time and effort compared to manual categorization.
Applications of Text Classification
Text classification has numerous applications across various domains, including:
Email categorization: Automatically sorting incoming emails into predefined categories, such as spam, promotions, or important communications.
Document tagging: Assigning relevant tags or labels to documents based on their content, facilitating efficient search and retrieval.
Sentiment analysis: Classifying text documents as positive, negative, or neutral based on the sentiment expressed in the content.
Text classification enables businesses to automate document categorization, improve information organization, and enhance the efficiency of various business processes.
6. Term Frequency: Understanding Word Importance
Term Frequency-Inverse Document Frequency (TF-IDF) is a statistical method used in text analytics to evaluate the importance of words in a document based on their frequency and rarity across a corpus of documents. This technique is widely used in natural language processing (NLP) and information retrieval to identify the most significant terms in a text.
Calculating TF-IDF
The TF-IDF score is calculated by multiplying the term frequency (TF) of a word in a document by its inverse document frequency (IDF) across the entire set. This score helps to highlight words that are important in a specific document but not common across all documents.
TF-IDF = TF x IDF
Where:
TF (Term Frequency): The frequency of a word in a document.
IDF (Inverse Document Frequency): The rarity of a word across the entire corpus.
Applications of TF-IDF in Text Analytics
TF-IDF has several applications in text analytics, including:
Text Classification: TF-IDF can be used as a feature extraction technique to classify documents into categories based on their content. By identifying the most important words in a document, businesses can automate the categorization process, improving efficiency and accuracy.
Information Retrieval: TF-IDF is commonly used in search engines to rank documents based on their relevance to a search query. By highlighting the most significant terms, TF-IDF helps to improve the accuracy of search results.
Topic Modeling: TF-IDF can be used to identify the most important words in a document and group them into topics. This helps businesses to understand the main themes and concepts in large text corpora.
Sentiment Analysis: TF-IDF can be used to identify the sentiment of a document by analyzing the frequency and importance of words with positive or negative connotations. This allows businesses to gauge sentiment and make data-driven decisions.

7. Event Extraction: Identifying and Analyzing Events
Event extraction is a technique used in text analytics to identify and extract specific events or occurrences from your data. Events can be defined as specific happenings or occurrences mentioned in text, such as meetings, appointments, or transactions. This technique helps businesses to gain insights from the data by focusing on significant events.
Techniques for Event Extraction
There are several techniques used for event extraction, including:
Rule-based Approaches: These approaches use predefined rules to identify events in text, such as regular expressions or keyword matching. Rule-based approaches are straightforward and can be effective for simple event extraction tasks.
Machine Learning-based Approaches: These approaches use machine learning algorithms, such as support vector machines (SVMs) or deep learning algorithms, to identify events in text. Machine learning-based approaches can handle more complex event extraction tasks and adapt to different types of data.
Hybrid Approaches: These approaches combine rule-based and machine learning-based techniques to identify events in text. Hybrid approaches leverage the strengths of both methods to improve accuracy and flexibility.
Applications of Event Extraction
Event extraction has several applications in text analytics, including:
Business Intelligence: Event extraction can be used to identify and analyze business events, such as sales or customer interactions. By extracting and analyzing these events, businesses can gain insights into their operations and make data-driven decisions.
Customer Service: Event extraction can be used to identify and analyze customer complaints or issues. By understanding the specific events mentioned in customer feedback, businesses can address issues more effectively and improve customer satisfaction.
Marketing: Event extraction can be used to identify and analyze marketing events, such as product launches or promotions. This helps businesses to understand the impact of their marketing efforts and optimize their strategies.
Social Media Monitoring: Event extraction can be used to identify and analyze events mentioned in social media posts, such as product reviews or customer feedback. This allows businesses to stay informed about customer opinions and respond to emerging trends.
By leveraging event extraction techniques, businesses can gain insights from their data and make more informed decisions.

Benefits of Text Analytics for Businesses
Text analytics empowers businesses to gain a profound understanding of their customers’ needs, preferences, and pain points. By analyzing customer feedback from various sources such as reviews, surveys, and social media, companies can uncover valuable insights that may not be apparent through traditional methods. A critical step in this process involves data gathering from both internal and external sources, utilizing methods like web scraping tools, integrating with third-party solutions, and employing data visualization tools to analyze and understand the collected data. This foundational activity ensures a comprehensive dataset for analysis, enhancing the accuracy and relevance of insights derived through text analytics.
Here are five ways that text analytics can benefit your business:
Improved customer insights
Enhanced decision making
Increased operational efficiency
Enhanced risk management
Improved product development
Improved Customer Insights
Personalizing Customer Interactions
Armed with these insights, businesses can tailor their interactions to individual customers, addressing their specific concerns and desires. This level of personalization leads to enhanced customer satisfaction and loyalty. A study by Epsilon found that 80% of consumers are more likely to make a purchase when brands offer personalized experiences.
Identifying Customer Sentiment
Text analytics also enables businesses to gauge sentiment, whether positive, negative, or neutral. By monitoring sentiment trends over time, companies can quickly identify and address issues before they escalate, as well as capitalize on positive sentiment to amplify their brand’s strengths.
Data visualization can be used for presenting sentiment trends.

Enhanced Decision Making
Text analytics empowers businesses to make data-driven decisions by extracting actionable insights from vast amounts of unstructured text data. By analyzing this data, companies can identify emerging trends, potential opportunities, and hidden risks that may impact their business strategies.
Competitive Intelligence
One key application of text analytics in decision making is competitive intelligence. By analyzing competitor mentions, product reviews, and industry discussions, businesses can gain a deeper understanding of their market position, identify areas for improvement, and stay ahead of the competition. Additionally, web scraping tools can be used for gathering competitor mentions and industry discussions.
Predictive Analytics
Text analytics can also be combined with predictive analytics techniques to anticipate future trends and customer behaviour. By analyzing historical text data and identifying patterns, businesses can make proactive decisions to optimize their strategies and mitigate potential risks.
Increased Operational Efficiency
Implementing text analytics can significantly boost operational efficiency by automating manual tasks and enabling faster processing of large volumes of text data. This automation frees up valuable time and resources that can be allocated to more strategic initiatives.
Streamlining Customer Support
One area where text analytics can greatly improve efficiency is customer support. By automatically categorizing and routing customer inquiries based on their content, businesses can ensure that each inquiry is handled by the most appropriate agent, reducing response times and increasing first-contact resolution rates.
Optimizing Business Processes
Text analytics can also be applied to internal business processes, such as analyzing employee feedback or identifying bottlenecks in workflows. By gaining insights from this data, businesses can optimize their processes, improve employee satisfaction, and ultimately drive better business outcomes.

Enhanced Risk Management
Text analytics plays a crucial role in identifying and mitigating potential risks that may impact a business. By analyzing various text sources, such as news articles, social media posts, and regulatory documents, companies can stay informed about emerging risks and take proactive measures to address them.
Early Warning Systems
Implementing text analytics as part of an early warning system can help businesses detect potential crises, such as product defects, supply chain disruptions, or reputational risks, before they escalate. This early detection allows companies to develop effective response strategies and minimize the impact on their operations and brand image.
Improved Product Development
Text analytics can provide valuable insights into customer preferences and expectations, enabling businesses to develop products and services that better align with market demands. By analyzing customer feedback, reviews, and discussions, companies can identify unmet needs, emerging trends, and areas for innovation.
Voice of the Customer
Integrating text analytics into the product development process allows businesses to capture the true voice of the customer. By understanding the language customers use to describe their needs and experiences, companies can develop more customer-centric products and features that address real pain points and deliver greater value.

How Does Text Analytics Work?
Text analytics involves preprocessing, feature extraction, model training, and interpretation. Natural Language Processing (NLP) techniques are used to understand and analyze text data. Text analytics can uncover insights, patterns, and relationships in unstructured data.
Text Preprocessing: Cleaning and Preparing Text Data for Analysis
Before any analysis can be performed, text data must be cleaned and preprocessed. This involves several steps, including:
Tokenization
Tokenization is the process of breaking down text into individual words or phrases, known as tokens. This is a crucial step in text analytics, as it allows the system to identify and analyze individual components of the text.
Removing Stop Words
Stop words are common words that do not add much meaning to the text, such as "the," "and," or "a." These words are typically removed during preprocessing to focus the analysis on more meaningful terms.
Stemming and Lemmatization
Stemming and lemmatization are techniques used to reduce words to their base or dictionary form. For example, “running,” “runs,” and “ran” would all be reduced to the base form “run.” This helps to normalize the text and improve the accuracy of the analysis. Additionally, using statistical analysis can further enhance the accuracy of the analysis.
For example sake, here’s an example Python code snippet that illustrates some common preprocessing steps for text analytics:
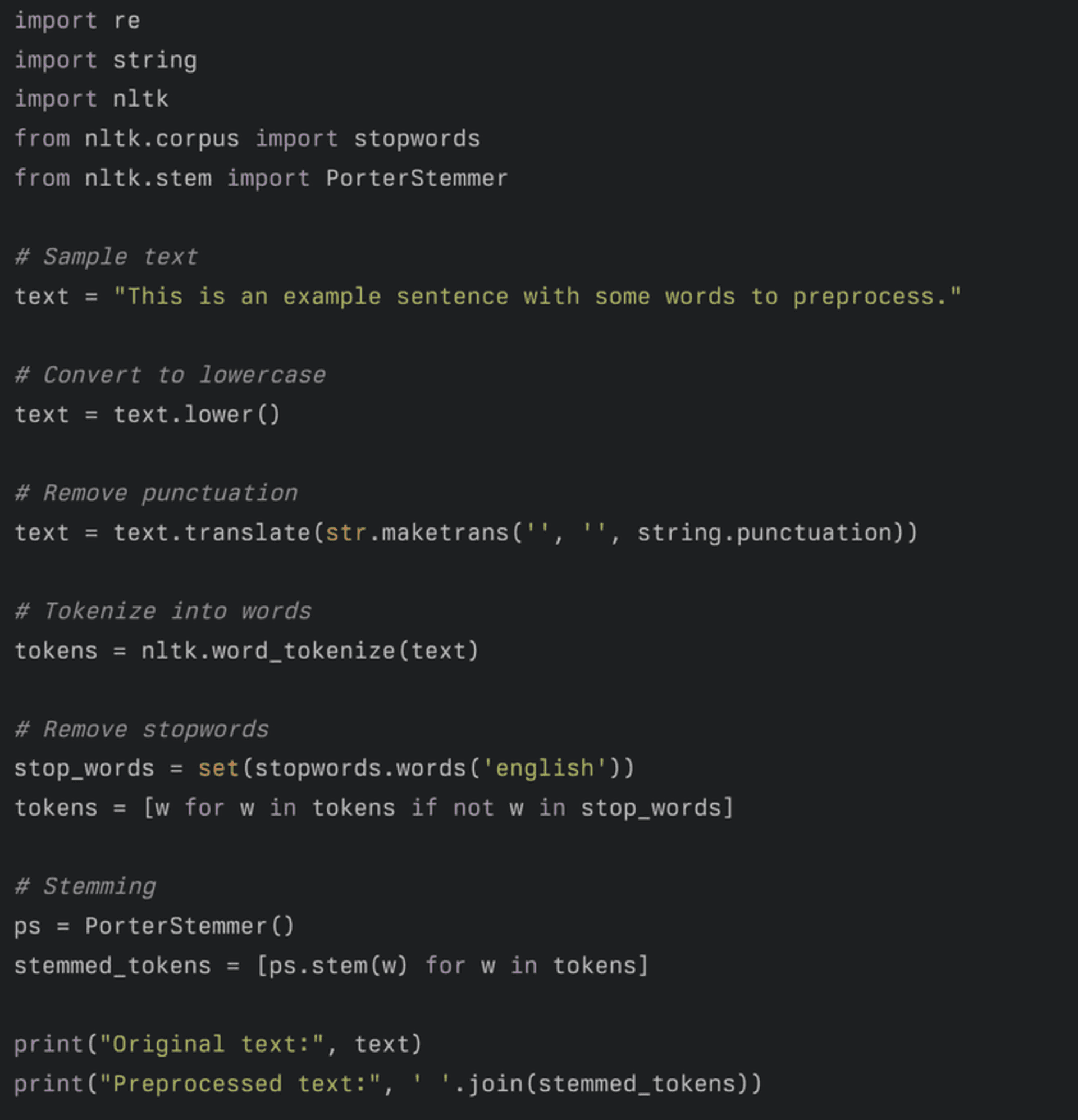
With a text analytics tool, here’s what each step would perform in the back-end:
Convert to lowercase: Converts the text to lowercase for consistency.
Remove punctuation: Removes all punctuation marks from the text using the string module.
Tokenize into words: Splits the text into individual words (tokens) using NLTK’s word_tokenize function.
Remove stopwords: Removes common words like “the”, “is”, “and”, etc., which don’t add much meaning to the text. This uses NLTK’s list of English stopwords.
Stemming: Reduces words to their base or root form (e.g., “running” becomes “run”) using NLTK’s PorterStemmer.
The output of this code would be:

Note that this is just one example, and the specific preprocessing steps may vary depending on the text analytics task and the characteristics of the data. The other preprocessing techniques like lemmatization and named entity recognition could also be applied depending on your use case.
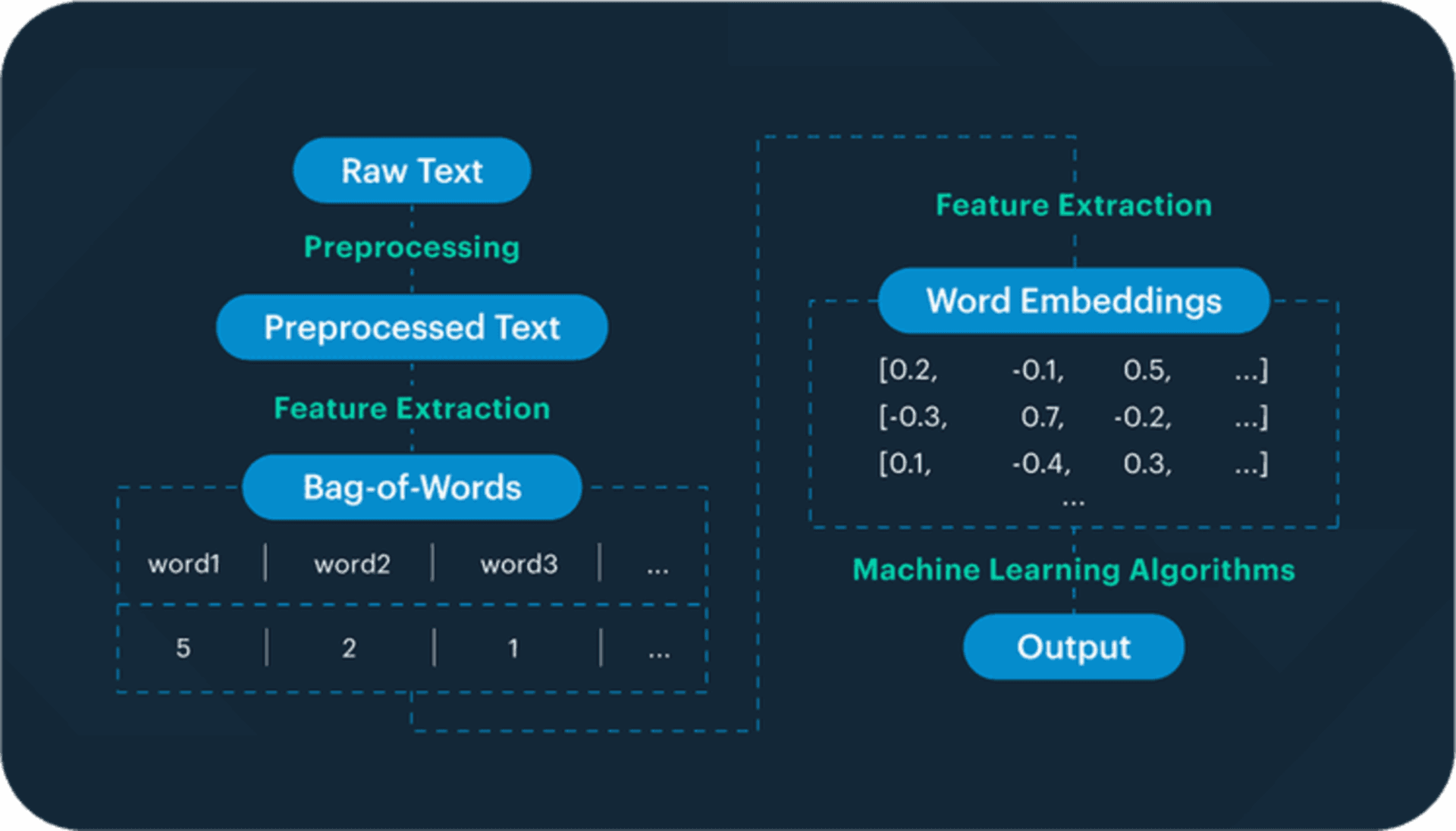
Feature Extraction: Converting Text into Numerical Features for Machine Learning
Once the text has been preprocessed, the next step is to convert it into a format that can be used by machine learning algorithms. This is known as feature extraction, and it involves representing the text as numerical features. Data visualization can be used to present these numerical features effectively.
One common technique for feature extraction is the bag-of-words model. In this approach, each unique word in the text is treated as a separate feature, and the frequency of each word is used to create a numerical representation of the text.
Another popular technique is word embeddings, which map words to high-dimensional vectors that capture their semantic meaning. This allows the system to understand the relationships between words and can lead to more accurate text analysis.
Here’s an example that illustrates the concept of feature extraction:
Model Training and Evaluation: Building and Assessing Text Analytics Models
With the data converted into numerical features, machine learning models can be trained to perform various text analytics tasks, such as:
Sentiment Analysis: Determining the emotional tone or opinion expressed in the text
Topic Modeling: Identifying the main topics or themes in a collection of documents
Named Entity Recognition: Extracting named entities, such as people, places, or organizations, from the text
Text Classification: Assigning predefined categories or labels to text documents
To ensure the accuracy and reliability of these models, they must be carefully evaluated using techniques such as cross-validation and holdout testing. This helps to assess the model’s performance and identify areas for improvement. Additionally, statistical analysis can be used to evaluate the models.
Interpretation and Visualization: Presenting Insights in an Understandable Format
The final step in the text analytics process is to interpret the results and present the insights using data visualization methods that are easy to understand and act upon. This often involves creating visualizations, such as word clouds, topic maps, or sentiment charts, that highlight key patterns and trends in the data.
Effective interpretation and visualization can help businesses quickly grasp the main takeaways from the text analytics process and make data-driven decisions based on the insights gained.
For further reading on text analytics techniques and applications, consider the following resources:
“Natural Language Processing with Python” by Steven Bird, Ewan Klein, and Edward Loper
“Text Mining with R: A Tidy Approach” by Julia Silge and David Robinson
“Applied Text Analysis with Python: Enabling Language-Aware Data Products with Machine Learning” by Benjamin Bengfort, Rebecca Bilbro, and Tony Ojeda

By understanding and leveraging these text analytics techniques, businesses can gain a competitive edge by extracting valuable qualitative insights from unstructured data, and make more informed, data-driven decisions.
How To Get Started with Text Analytics?
Define your business objectives and use cases for text analytics
Before diving into text analytics, it's crucial to clearly define your business objectives and use cases. What insights are you hoping to gain from analyzing text data? Are you looking to improve customer sentiment analysis, streamline document classification, or extract key entities from unstructured data? Understanding your specific goals will guide your text analytics strategy and help you select the most appropriate techniques and tools.
Consider the following questions when defining your objectives:
What business problems do you want to solve with text analytics?
What types of text data are most relevant to your goals?
How will text analytics insights be used to drive business value?
Explore and experiment with different text analytics techniques and tools
With your data collected and preprocessed, it's time to explore and experiment with various text analytics techniques and tools. There are numerous approaches to analyzing text data, each with its own strengths and limitations. Some common text analytics techniques include:
Sentiment Analysis: Determine the emotional tone or sentiment of the text, such as positive, negative, or neutral.
Topic Modeling: Discover the main themes or topics discussed in a collection of documents.
Named Entity Recognition (NER): Identify and extract named entities, such as people, organizations, or locations, from the text.
Text Classification: Assign predefined categories or labels to text documents based on their content.
Keyword Extraction: Identify the most important or frequently occurring words or phrases in a text.





