
You're in the exec review. NPS just dropped four points, and your dashboard says "product quality" is the top theme. That's it. No context, no root cause, nothing to tell the CFO.
Meanwhile, your support team handled 40,000 tickets last month. Somewhere in there is a specific checkout bug, a billing change customers are furious about, a delivery partner issue that's been building for six weeks. None of it shows up in the survey, because it was never a survey question. Nobody has time to read it all manually.
Most text analytics software conversations skip straight past this gap. They talk about dashboards and sentiment scores, not the fact that most customers actually never get analyzed, because nobody asked the right survey question to capture it. This guide is about closing that gap.
Table of Contents
What Is Text Analytics Software?
Text Analytics vs. Text Mining vs. NLP: What's the Difference?
Core Capabilities of Text Analytics Software
Text Analytics Software: Tool Categories
How to Choose Text Analytics Software
How Text Analytics Software Works
Why Text Analytics Software Matters for CX Teams
Use Cases: Where Text Analytics Creates Value
In Summary
FAQs
What Is Text Analytics Software?
Text analytics software uses artificial intelligence and natural language processing (NLP) to extract meaning, themes, and signals from unstructured text, including text data and other textual data such as customer feedback, support tickets, product reviews, call transcripts, and social mentions. It converts raw customer language into structured data and valuable insights that a CX team can actually act on.
Good text analytics software does more than tag sentiment. It finds what you didn't know to look for, links themes to the CX scores that move with them, and processes every customer interaction rather than a sample of them. That last part matters more than almost anything else on this list. Most teams are not analyzing the full corpus of what their customers say. They're analyzing the slice that arrived in a structured format: a survey response, a star rating, a closed-ended question. Text analytics software exists because the other 80 to 90% of enterprise data is unstructured, sitting in formats spreadsheets and dashboards were never built to read.
Text Analytics vs. Text Mining vs. NLP: What's the Difference?
These terms get used almost interchangeably in vendor marketing, and for a CX practitioner, evaluating the precise academic distinction matters less than understanding what's happening at each layer.
NLP is the computational engine underneath everything else. It's what helps computer systems interpret human language instead of just counting characters. Text mining is the extraction process built on top of NLP: finding patterns, keywords, and data points buried in raw text. Text analysis is the interpretation layer, where the software makes meaning rather than just counting word frequency. Text analytics is the business application layer, where analyzing text across large volumes of customer language turns all of that processing into a dashboard, a report, or a prioritized action list.
Core Capabilities of Text Analytics Software
It's tempting to evaluate text analytics tools as a feature checklist. Don't. The better question for each capability is: what business decision does this actually support? "Sentiment analysis" is a feature. "Sentiment analysis at the aspect level, so you know customers love your onboarding but hate your billing process" is a capability that changes what you do on Monday morning.
Sentiment Analysis
Basic sentiment analysis tells you whether a piece of feedback is positive, negative, or neutral. That's a start, but CX teams need more granularity than overall polarity, including signals of dissatisfaction in negative reviews as well as direct feedback. Aspect-level sentiment breaks a single piece of feedback into its component parts, so "the product is great but support took three days to respond" registers as positive product sentiment and negative support sentiment, in one pass. The better platforms also catch nuance: sarcasm, mixed sentiment within one response, and the difference between mild irritation and genuine anger.
Theme and Topic Extraction
This is arguably the core value proposition of text analysis for CX teams, because what your customers are actually talking about, distilled from thousands of individual comments into something a human can act on.
How themes get built is where tools genuinely diverge. Unlike modern bottom-up AI theme detection, traditional topic modeling groups feedback into word clusters that can be difficult to interpret. Keyword-based grouping sorts feedback into categories someone defined in advance, which means it can only find what your team already thought to look for. Bottom-up AI theme detection works the other way: it lets themes emerge from the data itself, surfacing patterns within your team predicted. Your support team is suddenly fielding complaints about a delivery partner you don't even have a category for, a keyword-based tool won't catch it. A bottom-up system will, because it's not constrained by a taxonomy built before the problem existed.
Trend Detection
Trend detection tracks how theme volume and sentiment move over time, which is what lets a team catch an emerging issue at 200 mentions instead of discovering it at 2,000, after it's already showing up in your NPS verbatims and your Trustpilot reviews. The value here is speed. Analysis that surfaces a problem three weeks after it started is reactive analysis, and reactive analysis is expensive analysis.
Entity Recognition
Entity recognition, including named entity recognition, pulls specific, named things out of unstructured text documents: product names, feature names, competitor mentions, and entities such as people, organizations, and locations where relevant. This matters operationally because it's what lets a platform route a specific complaint to the team that can actually fix it, rather than dumping every theme into one queue.
Text Classification and Tagging
Classification sorts feedback through text classification and text categorization, whether into pre-defined or AI-generated groups; the backbone of ticket routing, SLA management, and consistent reporting across a VoC program; text categorization is a supervised machine learning approach used for classification and routing. It's a less flashy capability than sentiment or theme detection, but it's the connective tissue that makes the rest of the system operational rather than just descriptive.
Most platforms surface themes based on taxonomies a team built before they'd seen the data, which means they're structurally limited to finding what was expected. That's the difference between a reporting tool and a signal detection layer, and it's worth holding onto as you read the rest of this guide.

Text Analytics Software: Tool Categories {#tool-categories}
The market isn't one category; it's several, and conflating them is how a lot of buying decisions go sideways. Here's how the landscape actually breaks down.
AI-Powered Conversation Intelligence Platforms
This is the category where text analytics capability runs deepest and where the CX relevance is highest. These platforms analyze unstructured feedback at scale, across every customer channel, surfacing themes that emerge from the data itself rather than from a pre-built set, and tying those themes directly to experience metrics.
Kapiche sits in this category. It's built for CX and support leaders at mid-market to enterprise B2C organizations who've outgrown survey sampling and keyword-based tagging. The platform processes 100% of customer conversations, calls, chat logs, reviews, and verbatims, and uses AI to surface themes that come from the data rather than from a pre-built taxonomy in a way that closely resembles modern conversation analytics software. Where rule-based platforms typically need weeks of taxonomy configuration before they produce a single insight, Kapiche returns first results within days of connecting data, and customers drill from any theme down to the individual verbatim that generated it rather than trusting a black box. One Head of Research and Insights described using Kapiche this way to realign their thinking about what they expected was driving NPS, but what the team assumed was driving it directly: Kapiche turned unstructured feedback into clear, quantified insights and made it possible to identify key themes even without predefined scores to anchor to. Kapiche isn't positioned to replace Qualtrics or Medallia. It sits alongside the unstructured and conversation intelligence layer that gives a survey program its score and context.
Enterprise CX Platforms with Text Analytics Modules
Medallia and Qualtrics both bundle text analytics into broader experience management suites. For organizations already embedded in one of these ecosystems and looking for a single platform rather than a best-of-breed stack, this is often the path of least resistance. Medallia's text analytics module has been recognized as a leader in the Forrester Wave for Text Mining and Analytics, and Qualtrics Text iQ provides NLP-driven theme detection tied directly into XM program data. The trade-off is that text analytics here is a module inside a survey-first platform, not the core product, which shows up in how deeply it processes non-survey channels.
Specialized NLP and Feedback Analytics Platforms
Between the enterprise suites and the general-purpose APIs sits a tier of purpose-built text analytics tools. Chattermill focuses on unified CX analytics with strong multilingual handling, but teams comparing these approaches often evaluate Kapiche vs Chattermill directly to understand the trade-offs in coverage and insight depth. Thematic is built around transparent, auditable AI, with research teams who can see and adjust how themes get constructed, making text analytics results easier to validate and audit, and there’s now an entire ecosystem of text analysis software tools in 2026 positioned to serve different maturity levels and budgets. SentiSum is oriented toward support operations specifically. Each has a fairly distinct primary audience: Thematic for research teams, Chattermill for unified CX reporting, SentiSum for support operations specifically. If your core text analysis capability is going to require a more targeted price point.
General-Purpose NLP APIs and Libraries
For teams with in-house data science capacity, open-source libraries like spaCy and Hugging Face, or APIs like Google Cloud Natural Language and IBM Watson Natural Language Understanding, provide the raw processing layer, but you’ll still need to design the overall text analysis approach to turn that output into something a CX team can use. They're flexible and powerful, but they're a foundation, not a finished product. Turning that output into business-grade system insights is typically a months-long engineering project, not a days-long one. For most CX teams trying to move quickly, this path needs more overhead than it saves.
How to Choose Text Analytics Software
Most buying guides hand you the same generic checklist: accuracy, ease of use, customization, support. None of that is wrong, but none of it is actually separates platforms at the point of decision either. If you want a market-level view of specific vendors, shortlists of top text analysis software tools can help, but here's the checklist worth walking into a vendor demo with.
AI Approach: Bottom-Up or Top-Down?
This is the single most important and most under-discussed criterion. Does the platform require you to pre-define a taxonomy before it can analyze anything, or can it adapt more easily as new data arrives? Rule-based and keyword-based tools need upfront configuration by design, they can only find what someone already thought to categorize, while machine learning approaches learn patterns from the data instead of relying only on predefined rules. AI-powered bottom-up analysis surfaces what's actually in the data, including the things nobody anticipated. For any team dealing with real volume across multiple channels, this single distinction will matter more than almost anything else on this list.
Coverage: What Data Sources Can It Connect?
Ask directly: does this tool connect to where your customers actually talk? Survey platforms like Qualtrics, Medallia, and SurveyMonkey are table stakes, especially if you’re running a mature NPS text analytics program and need to understand what’s driving score changes over time. Helpdesk systems like Zendesk, Salesforce, and Intercom, review platforms, online reviews, social media posts, news articles, social media comments, social feeds, and call transcripts are where most of the real signal lives, and they’re also the backbone of any move from survey-centric VoC to VoC 2.0 based on conversations. The breadth of what a tool can ingest determines whether you're analyzing your full customer voice or just the structured slice of it that happened to come through a survey link.
Transparency: Can You See How Themes Are Built?
A black-box theme is hard to defend in front of a skeptical executive, which is why customer stories that show transparent analysis, like Kapiche’s CX customer success case studies, tend to focus on verbatim-level traceability as much as on the metrics themselves. The platforms worth shortlisting let you drill from the theme straight down to the individual customer comments that built it. Ask vendors directly: can I see why this theme was created? Can I edit it if it's wrong? Can I trace a specific complaint back through the analysis to its source? If the answer is no, you're building a dashboard you'll eventually have to take on faith.
Time to Value: What Does Setup Actually Require?
Rule-based platforms often need weeks of taxonomy configuration before they produce a usable insight. AI-powered platforms without pre-built models should be returning first insights within days of connecting your data, and specialized customer feedback text analytics software is designed to shrink that window even further. Push every vendor for a realistic time-to-first-insight number based on your actual data volume, not a generic sales deck timeline.
Metric Linkage: Does It Connect to Your KPIs?
A list of themes ranked by frequency isn't the same as a list of themes ranked by impact, especially when you’re trying to understand the specific drivers behind NPS performance rather than just how often something gets mentioned. Look for platforms that tie theme volume and sentiment directly to NPS, CSAT, CES, or churn, so the team is prioritizing fixes based on what's actually moving the numbers, not just what's mentioned most often.
How Text Analytics Software Works {#how-it-works}
You don't need to understand the internals of an NLP model to evaluate whether a vendor's approach is sound, but it helps to know what's actually happening between a customer's comment and the dashboard you see, and how that maps to standard text analysis techniques and workflows.
Step 1: Data Ingestion
The software pulls in raw text from everywhere customers communicate: survey responses, support tickets, chat logs, review sites, call transcripts. Coverage starts here. A tool that only connects to two of five sources is only ever going to give you two-fifths of the picture.
Step 2: Data Preparation
Raw text gets cleaned and standardized before analysis: stripping irrelevant characters, fixing formatting issues, identifying the input language for multilingual content, and normalizing language variations so downstream work starts with accurate language identification. It's an unglamorous step, but a weak one here degrades everything downstream.
Step 3: Tokenization and Parsing
The text gets broken into its component parts, with sentence breaking used before parsing longer text into individual sentences, and the software then uses syntax parsing to map the grammatical relationships between them after the text has been segmented. This is what lets a system understand context rather than just counting how often a word appears.
Step 4: Feature Extraction
The system pulls out what actually matters: entities, key phrases, topics, sentiment indicators, and may reduce words to their dictionary form during preprocessing or feature extraction. Modern machine learning models, including deep learning algorithms, improve extraction accuracy on ambiguous language. Modern AI-powered platforms run this step using large language models trained on enormous text corpora, which is exactly why they outperform keyword-based rules on ambiguous, sarcastic, or context-dependent language.
Step 5: Analysis and Theme Grouping
Extracted features get grouped into themes and categories. In practice, this text analytics task can be handled with machine learning algorithms rather than only keyword rules, which helps models learn patterns from training data instead of relying on fixed matches. Rule-based tools group by keyword match, so two different phrasings of the same complaint can end up in two different buckets. AI-powered tools group by meaning, and sentence chaining can connect related ideas across separate comments or sentences when grouping themes, so those same two phrasings land in the same theme. This is the step where the bottom-up versus top-down gap shows up most clearly: a pre-built taxonomy can only sort what it was designed to expect, while AI-powered grouping surfaces themes a taxonomy would have missed entirely.
Step 6: Insight Delivery
Results surface as dashboards, reports, and alerts, and vendors will often back this up with detailed text analytics platform FAQs covering data sources, integrations, and security so teams know what to expect in production. The strongest platforms don't stop at a theme list, they link those themes to NPS, CSAT, and churn, so the team understands not just what customers are saying, but which of those things is actually moving the metrics leadership cares about.
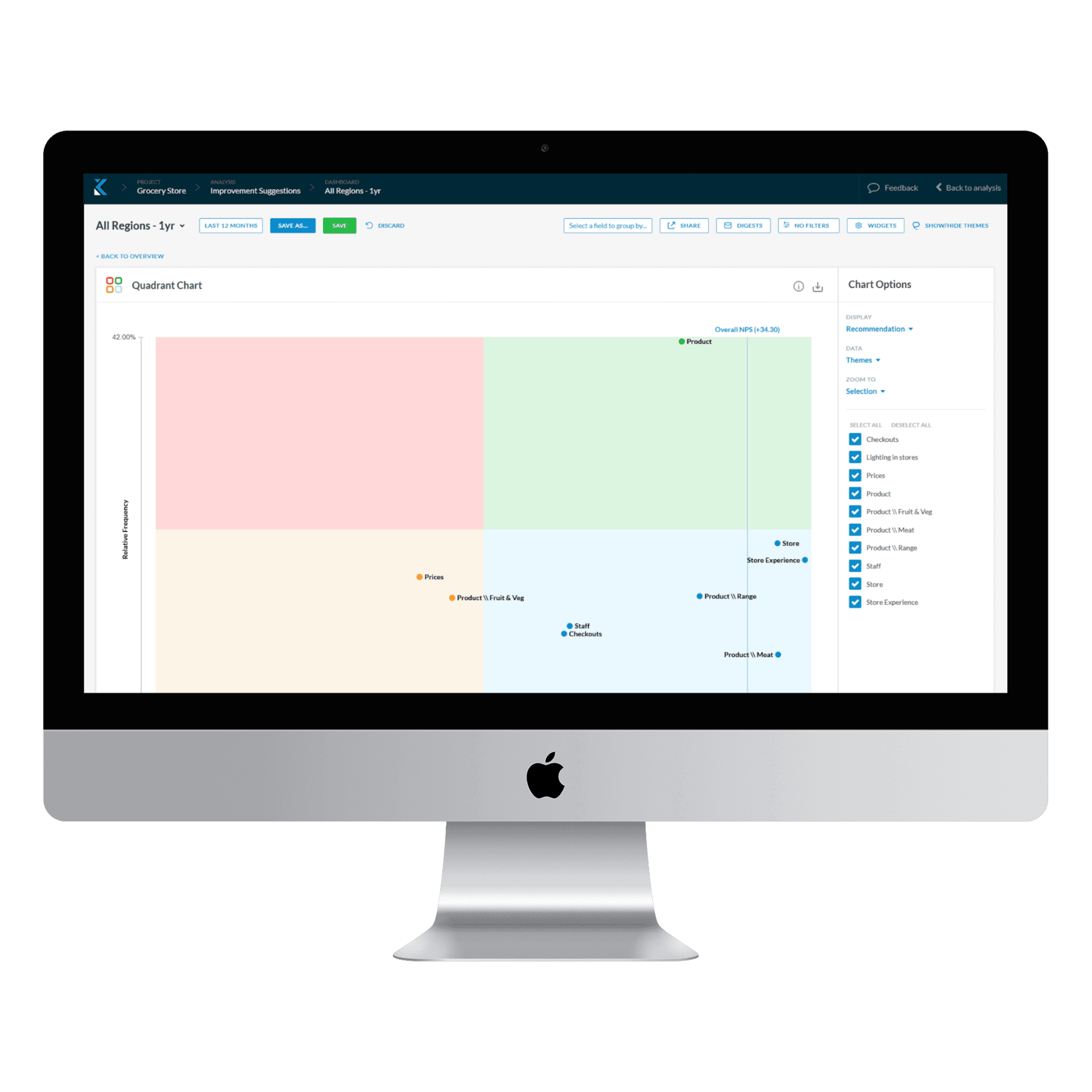
Why Text Analytics Software Matters for CX Teams
Turn Unstructured Feedback into Actionable Intelligence
No team can manually read thousands of responses, tickets, and calls a month. The right platform processes the full volume and surfaces what actually matters, turning text data into actionable outputs and deeper insights instead of just a short, prioritized list of themes someone can act on this week, which is exactly what modern VoC feedback analytics platforms are built to deliver.
Detect Issues Before They Become Crises
Real-time trend detection is what separates catching a problem at 200 mentions from discovering it at 2,000, after it's already a viral complaint thread, and it’s a core promise of enterprise-grade conversation analytics platforms that monitor every interaction rather than a sampled subset. That gap is the difference between proactive CX and weeks of reactive firefighting.
Connect Customer Language to Business Metrics
The useful question isn't just what customers are talking about; it's what's actually moving NPS, CSAT, or churn. Text analysis that links themes to metrics turns a list of complaints into a prioritized investment case, which is a very different document to bring into a budget conversation and is central to how customer feedback analysis platforms demonstrate CX ROI.
Process Every Channel, Not Just Surveys
Surveys capture a fraction of what your customers actually tell you. Text analytics tools that process support tickets, reviews, call transcripts, and social listening data show you the complete picture instead of a sampled one, especially when modern platforms process text data from multiple channels at large volumes and include AI-powered support call analysis as part of the workflow. Customer Experience Management is projected to be the largest application segment of the entire text analytics market by 2035, which tells you where the buying pressure is heading: toward tools that cover the full conversation, not just the 3 to 5% of customers who fill out a survey.
Build Confidence for Executive Conversations
Being able to drill from a theme like "billing issues" down to the actual verbatim, "I was charged twice and nobody fixed it for three weeks", is what lets a CX leader present findings to senior stakeholders without getting picked apart over a black box. A dashboard you can't explain isn't defensible insight surviving scrutiny.

Use Cases: Where Text Analytics Creates Value
Customer Feedback Analysis
NPS verbatims, CSAT open-ends, post-purchase surveys: text analysis processes the full corpus of open-ended responses in customer feedback analysis, a common CX and market research workflow used to gather consumer insights, surfacing recurring themes and linking them back to what's driving the score. It replaces manual verbatim coding and the word-cloud dashboards that show what you mentioned without ever telling you what matters.
Support Ticket Intelligence
High-volume, untagged support tickets carry some of the most unfiltered customer signal a business generates, precisely because nobody's curating what gets written in a ticket. Text analysis auto-categorizes that volume, catches emerging issue spikes, surfaces root causes, and routes tickets to the right team. The useful insight isn't "billing complaints are up 20%." It's "billing complaints are up because of a specific invoice template change that went live three weeks ago."
This is also where the coverage gap is most visible day to day. One Director of Customer Solutions described their team's shift this way: taking 600 calls a day used to mean relying on two quality coaches to spot-check a fraction of them. Processing every call instead, they said, gave the team insight into all of it and changed how the entire service model operated, moving from a sampled view of customer interactions to a complete one.
Product Review Analysis
App store reviews, G2 and Trustpilot pages, retail reviews: text analysis surfaces consistent quality and feature themes across hundreds or thousands of reviews without anyone reading them manually. Useful for roadmap prioritization and for understanding how you stack up against competitors on the things customers actually mention.
Voice of Customer Programme Management
Organizations running a formal VoC program use text analysis to process multi-channel feedback at scale and deliver consistent reporting across business units, closing the loop between what customers said and what the business actually changed, which mirrors many of the best practices in an effective Voice of the Customer program. This is the core use case for a platform like Kapiche, and it's where the shift from survey-based VoC to full-coverage, AI-powered VoC matters.
Social Listening and Brand Monitoring
Tracking brand mentions, product sentiment, and competitor discussion across social and review platforms supports brand health tracking and reputation management, and many conversation intelligence software tools now bake these capabilities into their core offering. It's a real use case, just a secondary one for most CX and support teams whose primary signal comes from direct customer interactions rather than public chatter.

In Summary
The real difference between text analytics software that functions as a reporting tool and software that functions as a signal detection layer comes down to one question: the AI approach. Bottom-up theme detection finds what you don't know to look for. Top-down, keyword-based tagging can only confirm what you already suspected.
That shift, from survey sampling to full conversation coverage, from pre-defined taxonomies to AI-surfaced themes, from theme-level reporting to verbatim-level proof, is what separates the next generation of text analytics software from the last one. Kapiche is built for that coverage, bottom-up AI detection, and a direct line from any theme back to the conversation that created it, making it a strong fit for organizations that want to centralize Voice of Customer insights into a single, AI-powered hub.
See how Kapiche turns 100% of your customer conversations into actionable insights with an AI-driven customer intelligence platform. Watch the on-demand demo.
FAQs
What is text analytics software used for?
Text analytics software is used to extract themes, sentiment, and emerging issues from unstructured customer text so teams can act on it instead of just reading it. For CX and support teams, the most common applications are analyzing support ticket volume to find root causes, processing open-ended survey responses at scale, monitoring product reviews for recurring quality or feature themes, and tracking brand sentiment across social channels. The common thread is turning raw, unstructured language into something a team can prioritize and act on.
What is the difference between text analytics and NLP?
NLP, natural language processing, is the underlying computational engine that allows software to parse and understand human language in the first place. Text analytics is the business application layer built on top of that engine, the part that turns raw language understanding into themes, sentiment scores, and prioritized reports a CX team can actually use. In practice, NLP enables the machine to understand what's being said, while the platform built on top of it decides what to do with that.

How does text analytics software work?
At a high level, these platforms use computer systems to pull in raw text from data sources like surveys, tickets, and call transcripts, process large volumes of it with machine learning techniques, including deep learning, clean and standardize it, then break it down to identify entities, topics, and sentiment. From there, the workflow can include text categorization and other machine-learning-driven steps depending on the use case, grouping related feedback into themes either by keyword match or by underlying meaning if AI-powered, and surfacing the results as dashboards, reports, or alerts tied to business metrics. The section above walks through these steps in more detail.
What are the main types of text analysis techniques?
The core techniques are sentiment analysis, which detects emotional tone across customer text; topic and theme extraction, which groups related feedback into the subjects customers are actually discussing; entity recognition, which pulls out specific products, people, or competitor mentions; and text classification, which sorts feedback into categories for routing and reporting—while some simpler methods just flag a particular word or phrase, newer approaches use context more effectively—each of which plays a distinct role in a broader text analysis strategy. Most text analytics platforms run all four techniques together rather than offering them as separate standalone tools, which is why comprehensive conversation intelligence solutions can feel so transformative compared to point tools focused on a single method.
How is text analytics software different from sentiment analysis?
Sentiment analysis is one technique that lives inside the broader practice of text analytics, specifically the part that detects whether feedback reads as positive, negative, or neutral. Text analytics is the wider process: it includes sentiment analysis, but it also extracts themes, tracks emerging trends, recognizes named entities, and connects all of that back to business metrics like NPS or churn. Sentiment analysis is one ingredient. Text analytics tools deliver the full recipe.
Can text analytics software process data from multiple channels?
Yes, and this is exactly where coverage becomes the deciding factor between tools. Modern AI-powered platforms can process survey responses, support tickets, chat logs, call transcripts, online reviews, review platforms, social media posts, and social feeds, often all at once. The practical implication is worth sitting with: a team that only analyzes survey data is working from a small fraction of its total customer signal, since most customers never fill out a survey at all. Any platform worth evaluating should be judged against how much of that total signal it can actually reach, not just how well it analyzes the slice it's given. Some teams instead use data scientists to build a custom text analytics system rather than buy a platform.






